Base64
-
将二进制数据转成 ASCII 字符串 (“binary to text” scheme*)
-
在 CSS 中直接嵌入小图标或者在 Data URI
-
核心: 将字节转换为一个取字符于一个由 64 个可打印字符组成的集合的可打印字符串
然而 64 个字符只能映射 6 位比特,所以使用三个字节以便映射到长度为 4 的 base64 的字符串。如果字节数不是 3 的倍数则会出现补位需求,如果字节数模三余一,则二进制需要补 4 个 0;如果字节数模 3 余 2,则二进制需要补 2 个 0。计算过程如下
已知字节数模三余一:
$$ \text{Bytes Number} \equiv 1 \pmod 3 $$
由模运算性质可知, 可推知
$$ 8 \times \text{Bytes Number} \equiv 2 \pmod 3 $$
显然有
$$ 8 \times \text{Bytes Number} \equiv 0 \pmod 2 $$
我们知道 $gcd(2, 3) = 1$,因此可以根据中国剩余定理(CRT)得到:
$$ \begin{align} 8 \times \text{Bytes Number} &\equiv 8 + 0 \pmod 6 \ 8 \times \text{Bytes Number} &\equiv 2 \pmod 6 \ \end{align} $$
同理,已知字节数模三余二:
$$ \text{Bytes Number} \equiv 2 \pmod 3 $$
通过同样的过程可推得:
$$ \begin{align} 8 \times \text{Bytes Number} &\equiv 4 + 0 \pmod 6 \ 8 \times \text{Bytes Number} &\equiv 4 \pmod 6 \ \end{align} $$
所以需要将剩下的比特填充为 6 位进行 base64 编码:
- 字节数模三余一时,需要末尾填充 $6-2=4$ 位二进制
0 - 字节数模三余一时,需要末尾填充 $6-4=2$ 位二进制
0
base64 要求四个为一组, 不足四个的,填充
=。当字节数无法整除 3 时,生成的未加 padding
=的 base64 字符串也无法整除 4,计算过程如下$n \coloneqq \text{Bytes Number}$
$m \coloneqq \text{Base64 Output Length without padding ‘=’}$
当 $n \nmid 3$ 时,$n$ 可以取值:
$$ n = 3k + 1 \text{ or } n = 3k + 2 $$
相应的 $m$ 为:
$$ m = 4k + \lceil\frac{4}{3}\rceil \text{ or } m = 4k + \lceil\frac{8}{3}\rceil $$
显然 $m$ 无法整除 4, 当字节数 $n\equiv 1 \pmod 3$ 时,$m \equiv 2 \pmod 4$, 填充两个
=;当 $n \equiv 2 \pmod 3$ 时,$m \equiv 3 \pmod 4$, 填充一个=。于是通过填充
=可以告知二进制的填充情况:-
一个
= $\rarr$ 填充了两个零 -
两个
= $\rarr$ 填充了四个零
- 字节数模三余一时,需要末尾填充 $6-2=4$ 位二进制
为什么需要填充 =
RFC4648 说明了这个问题:

通常来说如果传输的数据大小无法被确定,padding(“=”)是需要用来保证生成正确的解码数据的。所以“=”是用于保证传输过程中错误的截断不会导致数据解读错误。
对于标准的带填充的 base64 编码后的数据,我们可以通过读取末尾 = 的数量去确定二进制补位的数量;然而对于省略了 = 的,我们需要计算 base64 字符串模四的余数与四的差确定二进制补位的数量。
Encoding Algorithm (Python 实现):
|
|
Decoding Algorithm (Python 实现):
|
|
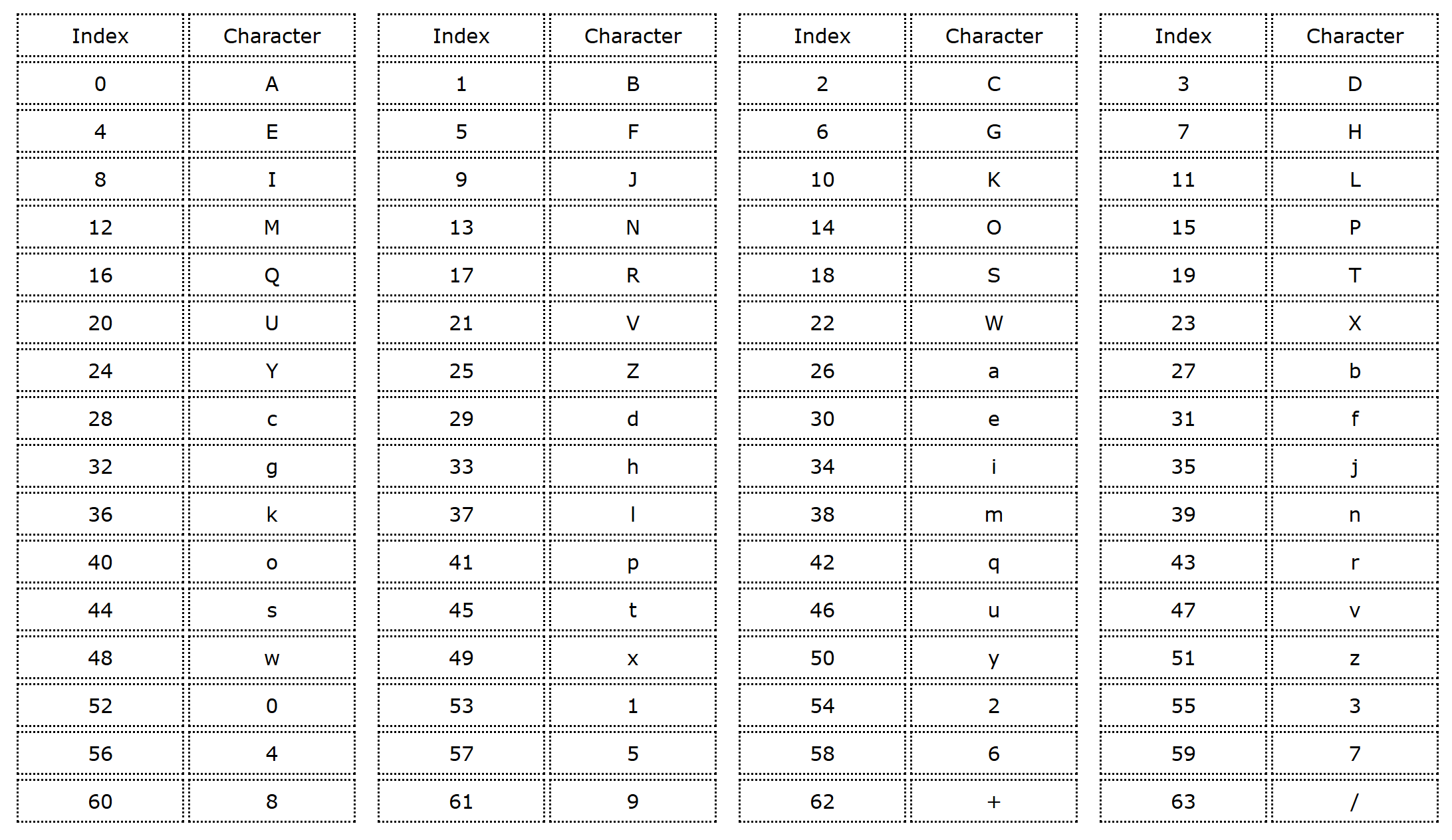
字符表查询操作(Python 实现):
|
|